Research Interests
Our research interests are in space systems, artificial intelligence, and systems engineering and design. Of special interest lately are: 1) new methods to leverage generative AI for automated design of complex systems; 2) new AI agents for human-agent collaborative decision-making to support various use cases, from systems engineers designing Earth observing satellite systems to astronauts resolving spacecraft anomalies; 3) new approaches for autonomous task planning and scheduling in spacecraft and sensor webs.
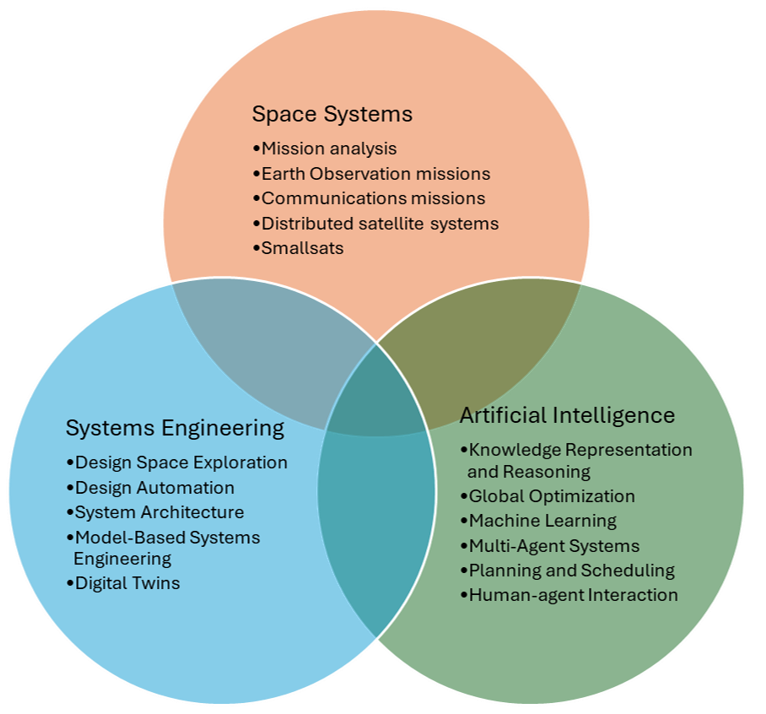
What do students in the SEAK Lab learn about?
Most students in the lab will be familiar with many if not most of the topics in the Venn diagram above, although the particular level of expertise for each topic will vary depending on the student.
Research Projects
Our research is funded by NASA, NSF, DOD, and industry. The following is an incomplete list of our recent and current research projects:
- AI-Assisted Design of Chiplet-Based Heterogeneous Processing Architectures (Lockheed Martin E&T/CTO, 2024–present)
- 3D-CHESS: Decentralized, Distributed, Dynamic and Context-Aware Heterogeneous Sensor Systems (NASA AIST 80NSSC22K1490, 2022-2025)
- Multi-Agent Anomaly Resolution System (NASA STTR Phase I and II 80NSSC24CA028 led by TRACLabs, Inc, 2022-2025)
- Virtual Assistant for Spacecraft Anomaly Treatment During Long-Duration Exploration Missions (NASA 80NSSC19K0656, 2019-2025)
- Collaborative Research: Knowledge And Data-Driven Design Of Mechanical Metamaterials (NSF CMMI-1825521, 2018-2021)
- TAT-C ML: Tradespace Analysis Tool for Constellations with Machine Learning (NASA NNH16ZDA001N-AIST, 2017-2019)
- The Daphne cognitive assistant for early formulation of Earth observation missions
- Intelligent data understanding for architecture analysis of entry, descent, and landing (NASA NSTRF NNX16AM51H, 2017-2021)
- Improved human-computer interaction for design of complex systems (NSF CMMI-1635253, 2016-2019)
- Design and Optimization of Space System Architectures: Applying and Extracting Lessons Learned (NASA NSTRF NNX16AM51H, 2016-2018)
- Constellation design for the NASA TROPICS mission (NASA NNH12ZDA006O-EVI3, subcontract from MIT Lincoln Lab, 2016-2018)
- Cityplot: Visualization of high-dimensional design spaces with virtual reality
- Human-machine collaborative feature extraction for engineering design
- Multi-objective design exploration of next-Gen Global Navigation Satellite Systems (GNSS)